June Native: Research Preview
Rajdeep Ghosh & Subhodip Roy
June Labs - October 2025
The future of voice AI isn't about making machines sound human - it's about making them understand emotion the way humans do. Today, we're sharing early insights from June Native, our research into audio-native language models that process speech directly, preserving the emotional depth that text cannot capture. The model operates on raw audio bytes, maintaining complete acoustic and emotional information throughout processing. Try the live demo.
Beyond Traditional Voice Pipelines
Current voice AI systems treat audio as an afterthought. They transcribe speech to text, process it through a language model, then synthesize it back to speech. Additionally, they require separate models for voice activity detection and turn prediction. This five-model pipeline loses what matters most: the hesitation in someone's voice, the emphasis that reveals emotion, the natural rhythm that makes us human. Each conversion strips away emotional nuance, and the cumulative delay makes real-time interaction feel mechanical.
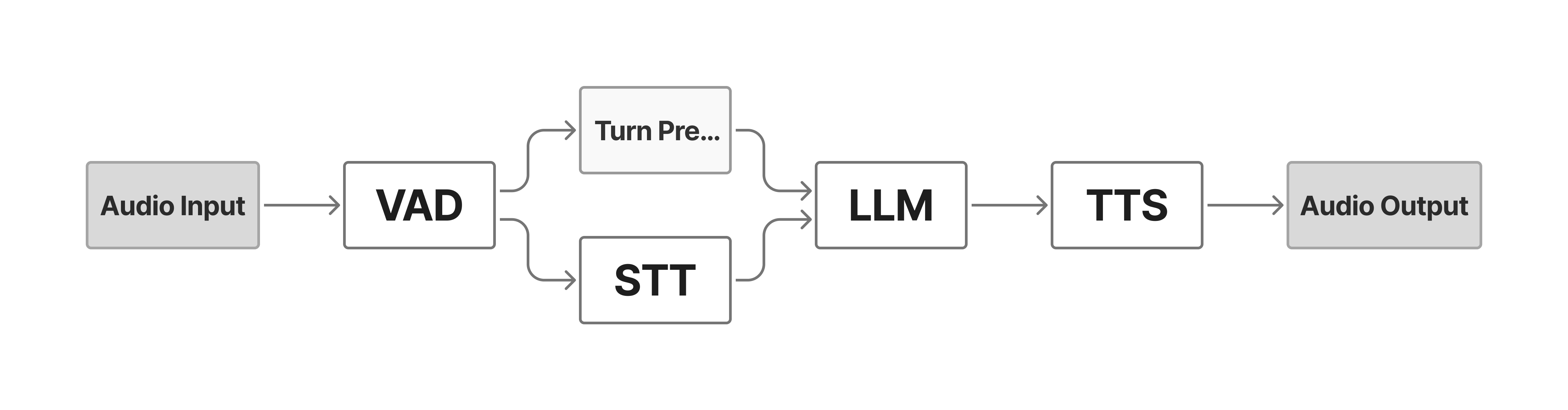
June Native takes a fundamentally different approach. Our model processes and generates audio directly in a single unified architecture, preserving the emotional richness of human speech throughout the entire interaction cycle. When you speak, June Native isn't just hearing words - it's understanding the complete emotional signal, with all its human nuance intact.
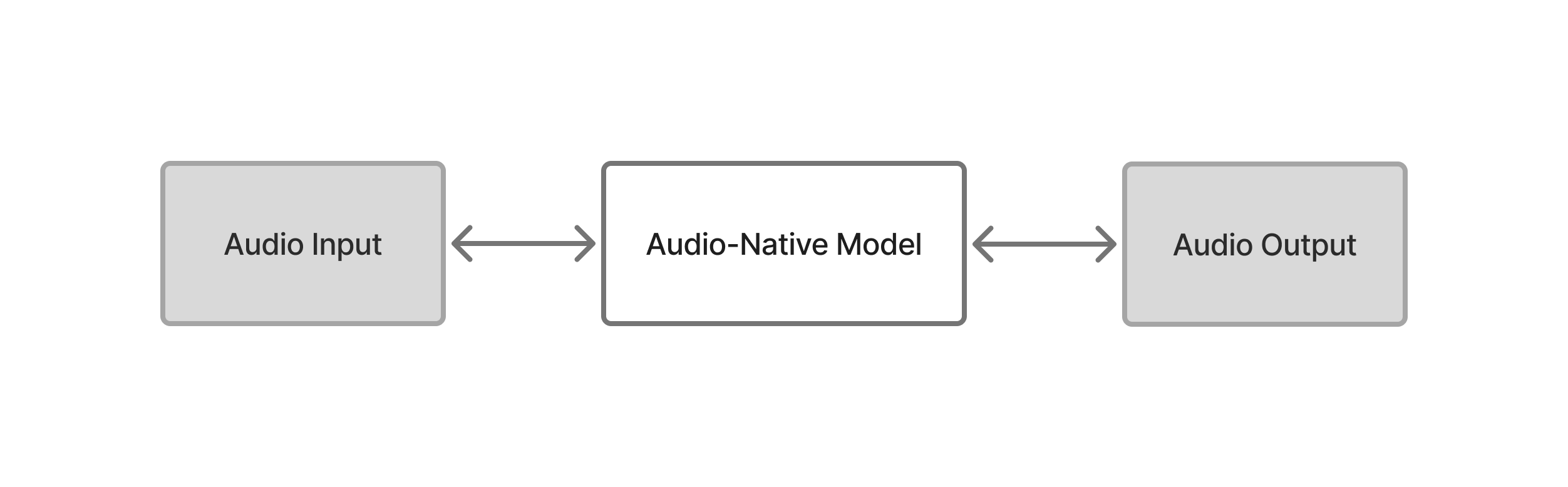
Full-Duplex Architecture
At the core of June Native is a full-duplex architecture that mirrors human conversation patterns. The model simultaneously listens and speaks, managing multiple audio streams in real-time. Even during apparent silence, the system remains active - generating what we call "silence tokens" that maintain conversational awareness and readiness to respond.
Time →
Listen: [audio tokens][audio tokens][silence tokens][audio tokens]
Speak: [silence tokens][audio tokens][audio tokens][silence tokens]
↑─────────── Simultaneous Processing ───────────↑
This design enables natural conversational behaviors: knowing when to interject, handling interruptions gracefully, and maintaining the subtle back-and-forth rhythm that makes dialogue feel natural. The unified architecture eliminates the need for separate voice activity detection and turn-prediction models - the system inherently understands conversational dynamics through its audio-native processing.
The Audio-Native Advantage
By maintaining audio representation throughout processing, the model retains:
Emotional Context: A slight tremor indicating uncertainty, rising intonation suggesting a question, the warmth that signals friendliness - these nuances flow naturally through our audio-native pipeline.
Prosodic Intelligence: The model understands and generates speech with appropriate stress, rhythm, and intonation patterns. It doesn't just say the right words; it says them the right way.
Acoustic Continuity: Background sounds, ambient noise, and even breathing patterns provide context that helps the model better understand and respond to the conversational environment.
Temporal dynamics: The precise timing and overlap that define natural conversation
Performance Characteristics
Our research prototype demonstrates:
- Sub-160ms latency: Response times in controlled environments
- Unified processing: Reduction in pipeline complexity and cost versus traditional systems
- Concurrent audio streams: Parallel processing of bidirectional conversation
- Cross-lingual operation: Language switching without mode changes
Technical Architecture
June Native employs a unified transformer architecture processing audio tokens directly from a neural codec's residual quantizer. The model operates on continuous audio streams with specialized attention mechanisms for temporal relationships.
The architecture maintains multiple representation layers within a single forward pass: lower layers handle semantic understanding while upper layers manage acoustic generation. By processing conversational context - including interruptions, overlaps, and acoustic environment - directly at the language model layer, the system develops an integrated understanding of both what is being said and how the conversation is unfolding.
This eliminates the cascading errors inherent in pipeline systems and enables the model to make response decisions based on complete conversational context.
Research Direction
June Native represents our pursuit of Emotional General Intelligence - AI systems that truly understand and respond with genuine empathy. This preview demonstrates the viability of end-to-end audio processing, though significant work remains in our research journey.
Voice AI should feel like human connection, not computation. With June Native, we're building toward that future.
Experience our latest model, June-Realtime, through the live demo.